In this project, I applied Denoising Diffusion Probabilistic Models (DDPM) to audio data. Diffusion models have been popular in image generation, but my focus was to adapt this method for audio processing, particularly for data augmentation and creative audio manipulation.
![]()
![]()
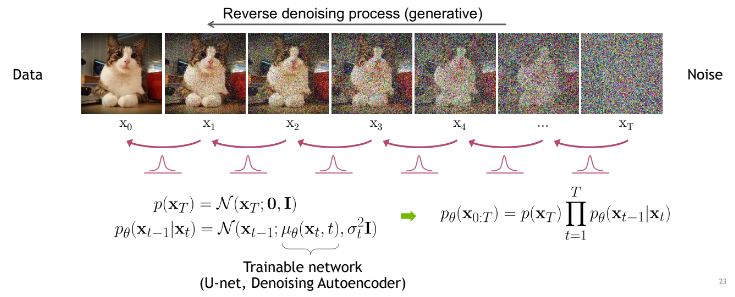 Example of diffusion on image.
Example of diffusion on image.
Non-Conditional Diffusion
The model I worked with is non-conditional, meaning it doesn’t require external guidance or inputs to generate or modify audio. My main focus was on experimenting with how adding noise to audio—over a series of steps—could transform or modify the audio. By learning how to remove the noise step-by-step, the model is able to alter audio in ways that might be useful for data augmentation and creative applications.
DDPM Diffusion Pipeline
I implemented two variations of the DDPM pipeline:
- Custom DDPM: This mode allows for the modification of existing audio by progressively adding different levels of noise. The more noise injected, the more the audio is altered.
- Standard DDPM: This mode generates new audio samples from scratch. Starting with pure noise, the pipeline gradually denoises the sample, reconstructing it into meaningful audio. This approach demonstrates the generative power of diffusion models for audio.
Tackling the Dataset Challenge
One of the key challenges in this project was the lack of large-scale music datasets. To address this, I used data augmentation techniques, including filtering, cutting, and merging audio samples. These audio processing methods allowed me to artificially expand the dataset by creating variations of the original audio. This approach was crucial for simulating a larger and more diverse dataset, especially when dealing with limited data availability.
Running on GPU
I ran the entire pipeline on a local GPU, and while the results were promising, I encountered some limitations due to hardware constraints. With a more powerful GPU, I believe the results could have been even better—especially when it comes to training with larger batches. Larger batches typically lead to more stable training and better model performance. That said, the outcomes were still very encouraging given the resources I had.
Next Steps: Lower Sample Rates
One important takeaway from this project is that training the model at a lower sample rate could greatly reduce the computational cost. By working with a lower resolution of audio, I could speed up the process without sacrificing too much quality. After processing, I’d apply upscaling techniques to restore the audio to a higher quality. This is definitely something I plan to explore further in future iterations of the project.
Looking Ahead: Conditional Diffusion
While this project focused on non-conditional diffusion, I’m excited about experimenting with conditional diffusion in the future. Conditional models would allow for more control over the generated or modified audio, providing more targeted transformations based on specific audio characteristics. This would open up exciting possibilities for fine-tuned audio manipulation.
Final Thoughts
Overall, I’m happy with how this project turned out. The diffusion pipeline worked well for audio modification and data augmentation. With larger datasets, better hardware, and further improvements, I think the results could be even better. I’m excited to experiment with conditional diffusion next.
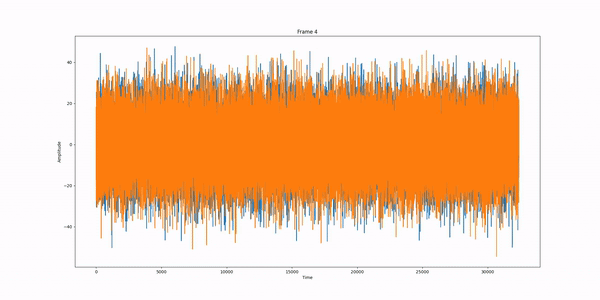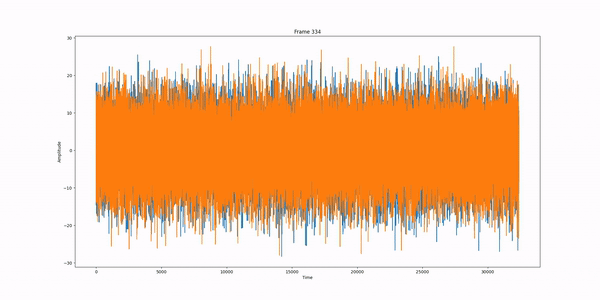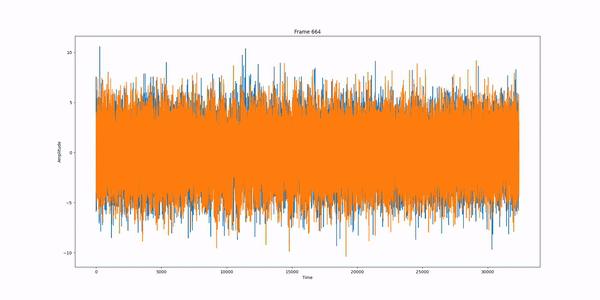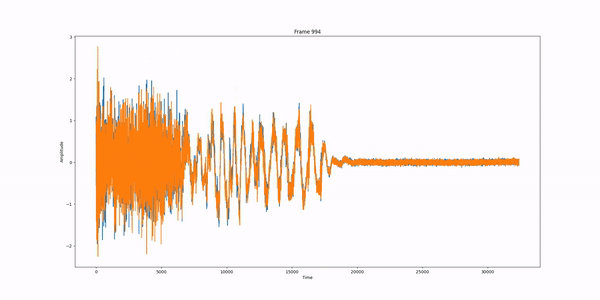
Example: Standard DDPM pipeline run, frame per frame.