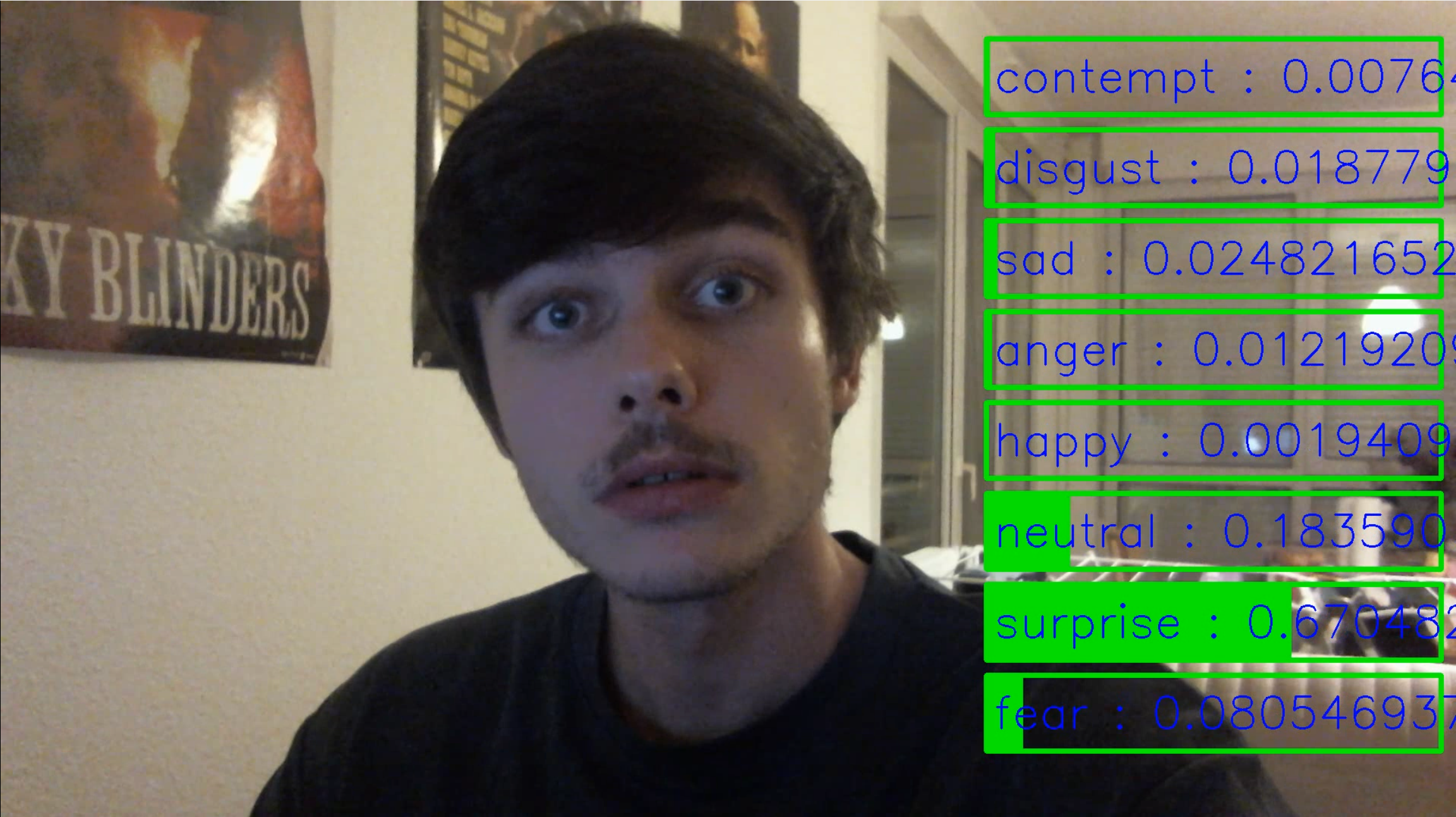
This was a relatively short but fascinating project where I experimented with Vision Transformers (ViT)—a model architecture I hadn’t explored much before. The main goal was to apply a pre-trained ViT for emotion classification. I learned a lot about how ViTs work and their potential applications in computer vision tasks.
Approach
I used a pre-trained Vision Transformer (ViT) and replaced the classification head with a new one for emotion classification. This let me use ViT’s feature extraction strengths while adding my own custom layer. The model ended up classifying facial emotions well, even with a short training time.
Key Takeaways
- Exploring ViTs: I was new to Vision Transformers, and this project helped me understand their structure and how they differ from convolutional networks.
- Transfer Learning: By using a pre-trained model and only retraining the head, I completed the project efficiently with good performance.
- Short but Impactful: Even though it was a short project, it was an interesting look at ViTs and showed me the power of transformers beyond NLP.
Conclusion
The main goal of this project was to use Vision Transformers (ViT) and gain hands-on experience with them. The emotion classification aspect was simply a pretext to explore and understand how ViTs work in practice. Despite being a short project, it provided me with a better understanding of transformers in computer vision and allowed me to learn new techniques along the way.
Resources
Here is the dataset used for training.
(and my surprised face)